ng-nodejs 偶发 502
ng + node 服务,导致 ng 报错:upstream 提前关闭连接?
大前提是 ng 作为反向代理,upstream 为 node 集群。
出错的触发条件是:某处发给 ng 一个带乱码的 url 请求,被 ng 转向 node 集群。
背景介绍
   随着部门的 web 接口不断增多,java 后端逐步向 node 迁移。在我大住宿,这个 web 接口有一个好听的名字:热狗。不,不对,它叫 hotdog。即从这个状态: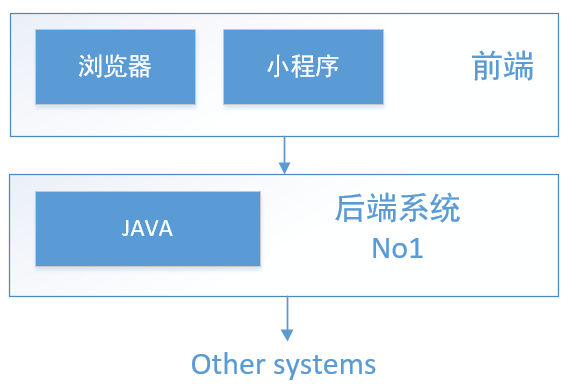
   变为了这个状态: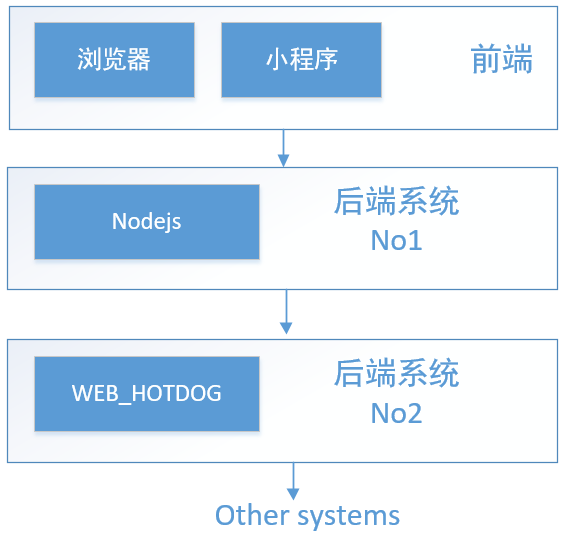
   我们需要做的,就是搭建 node 服务,作为客户端和 WEB_HOTDOG 的通讯桥梁。
   考虑到负载均衡,一般会采用类似 nginx 的软件作为反向代理。同时源服务器一般会有多台,所以经常看到这样的配置:
1 | upstream node_server { |
   即对 /interface/to/location 的请求会被转发到 upstream node_server 上,当然详细的配置还有很多。
故障重现
   配置好 ng,部署好工程,万事俱备,只差验收了。然而,当访问新增的 Node 接口时,总是__时不时__的返回 502!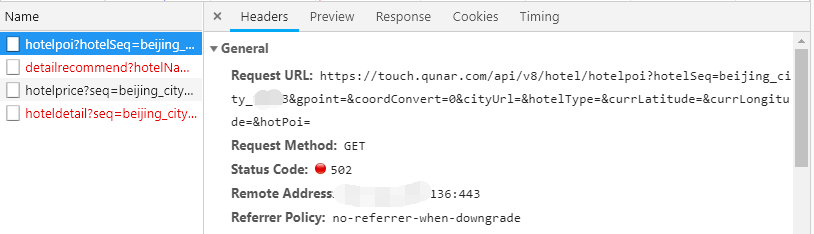
   还有一个现象:当一个接口 502 后,其它接口基本上也跟着 502(首屏会发 3 个请求)。但是直接 node 服务器的 IP+PORT 访问,一切都是那么的完美!既然有问题了,开始查问题!
fix problem
   接下来将以多个步骤,讲解 fix 的过程。
Step.1 ops 查 ng 日志
   首先 ops 贴了一份 ng 日志: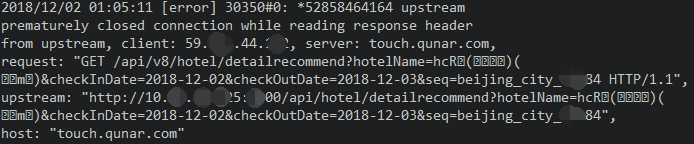
  ops 支持人员说:google 了下 意思大概是说这部分访问进来走的是 ng 上处于半连接的 tcp 连接,__导致服务没处理就关闭连接了__。所以我们看到是 502。我们可以先尝试__增加连接的超时时间__。
Step.1_result
   增加了超时连接后,依然出现 502。继续。
Step.2 Nodejs 服务端查日志
   作为大前端,查 node 日志肯定是我们基本功。守护程序使用的是 pm2。但是我们却意外地发现,并没有__看到任何 502 的请求进来__!并且查看到当时的系统负载很低,不会因为负载大而断链。也就说是,ng 返回给前端的 502 请求,__并没有进入到 node 服务器中__!这时候我们认为是 ng 转发有问题!联系 ops 继续看 ng。
Step.2_result
   失败,继续找 ops 定位问题。
Step.3 ops 修改到 upstream 为长连接
  ops 说,考虑到多种因素,一般连接到 upstream 都采用的是短链接,对于频繁访问的接口,可以尝试使用长连接。经过我们大前端的确认,node 服务器支持 HTTP1.1 的长连接,开始实验。
Step.3_result
   更为长连接后,502 情况依然存在。失败。
Step.4 查看 node 服务的超时处理
  ops 认为 node 服务在处理请求时,会有默认的超时处理。经过我们的确认,nodejs 的 http 服务器默认超时时间是 2min(我们并未手动更改超时时间),而出现 502 的情况是在请求发出后 1 秒内返回的。node 服务器代码内,我们并未手动返回 502 状态(如果能手动返回 502,那么说明请求已经到了 node 服务中间件,不可能出现没有请求日志的情况)。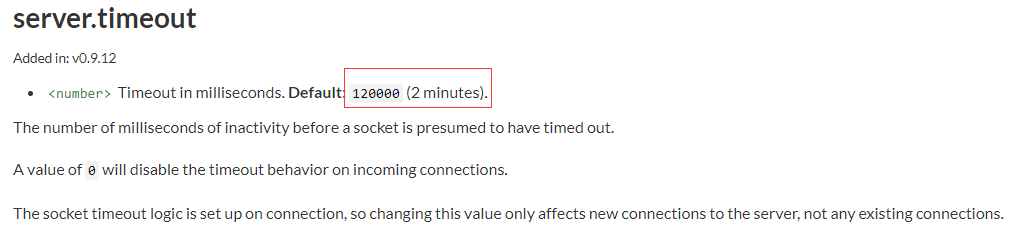
Step.4_result
  node 服务器并没手动返回 502 状态码,准确地说应该是没走到业务逻辑中就已经挂了。
Step.5 网络层面 — 抓包
   现在的问题是,ops 认为是 node 服务器有问题,我们认为是 ng 服务器有问题(确实各有各的道理),所以得找出是不是自身的问题。ops 决定采用抓包的方式,看请求转发过程中请求、响应情况。下图是 ops 提供的 ng 服务器抓包图: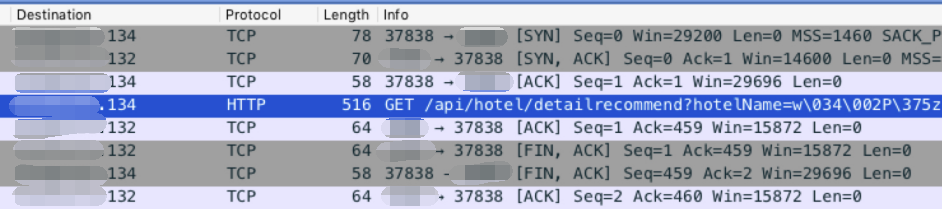
   由上图可以看出,ng 发出请求到 upstream 的服务端口(这里将简称 D 端口)后(就是当前 hover 的条目),D 端口监听的程序(node 服务器)没有给出相应,而是先回了个 Ack,然后直接发起 Fin,结束连接。ng 也回复 Fin,确定结束连接。对于 Ng 来说,upstream 没有返回任何东西,连响应头也没有,就给前端返回 502 了。找到了问题,下面就看这种情况产生的原因及处理方案了。
Step.6 两端各自的尝试
前端方案–node
   查日志过程中发现了大量的乱码,如下图:

   发现前端并未对非英文字符或其他特殊字符做 encode。在 encode 之后,抓包后未发现乱码,同时也并未再产生 502 的情况。(此时我已经觉得是 node 的问题了)。我的猜想是:含有特殊字符(或者叫非法字符)的 url 请求,当到达 node 的 http 服务时,在最底层 net 层就挂了,以至于传不到业务层(表现上就是肉眼不可见的请求日志)。
   为了验证猜想,我查了一下 Node-http 文档:http.Server 有一个 clientError 事件回调(只看到这么一个跟 Error 有关的 server 级回调)。于是我写了一个基本的 http 服务,并发送了一个如下的请求:
1 | const http = require('http'); |
1 | curl 'localhost:8888/api/hotel/detailrecommend?hotelName=7)�R�(fI7��) ┳ ┓┏ ┯ ┓┌ ┬ ┐╔ ╦ ╗╓ ╥ ╖╒ ╤' |
   这里只是模拟乱码的出现,不一定非是这些字符。然后 node 服务打出的日志:
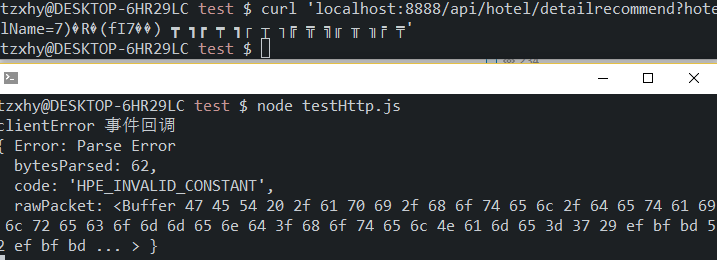
   确实是 server 层面的出错了。我们看看这个 rawPacket 是什么:
1 | GET /api/hotel/detailrecommend?hotelName=7)�R�(fI7��) ┳ ┓┏ ┯ ┓┌ ┬ ┐╔ ╦ ╗╓ ╥ ╖╒ ╤ HTTP/1.1 |
   这就是出错的请求头。
   找到了问题所在,我们可以处理这个问题了:__对 server 添加 clientError 事件,打点记录错误请求信息,并将该 socket 以状态码 400 返回(给 ng 服务器)__,不处理这个事件的话,socket 会 hang 住,然后由 tcp 层面自动关闭(这纯属我瞎逼逼的)。问了一下 java 的同学,说 java 中是会处理非法字符的,但 node 确实是没有处理,还是说留了个__clientError__让我们自己处理?黑人问号脸。。
ops 方案–ng
   至于为什么 node 服务器未响应,导致用户请求的其它请求也 502 了?ops 同学给了如下解释:nginx 被动检查导致,过多的错误会让 ng 认为 server 下线了,于是在一个 fail_timeout 周期内的请求都被 ng 直接返回 502 码,不管该请求是不是非法请求。ops 同学继续补充:让 touch 域名的配置尽快迁移到 OpenResty。OpenResty 没有这个问题,它针对每个请求都是独立的,只依赖 healthcheck 状态,而不会依赖上一次请求的成功与否。
总结
   这一次的故障,让我和多个部门的同学一起定位问题。从前端到 ng,从 ng 到 node,从业务层面到网络底层,都有了更深的理解。错误不可怕,可怕的是找不到哪里错了。顺便记一下__ng+node__模式下的坑点:
- node 处理中要对所有异常进行处理,不管是业务层的,还是底层的。如果一开始就监听了 clientError 事件,那么解决这个问题就更加显而易见。
- ng 处理请求失败要结合具体场景,而不是所有 upstream 都是一个通用的模板。
   同时也 get 到了新技能:
- 服务器抓包中使用,tcpdump 命令进行抓包,常用的:   即可捕获所有 ng 打过来的请求,并保存在 ng-request.pcap 文件中,拉到本地用 wiresharp 瞅一眼,就知道 tcp 层面上的网络交互情况。
1
tcpdump -vv -nn host <ng server ip> -w ng-request.pcap